

When authors come to me for a book cover commission they generally come at me from two very different directions.
Either they’ve seen my work and say to themselves: I’ll have some of that, let this kid go wild and create something amazing for my book, I’m sure he’ll do good work whatever it is.
Or maybe they will say: I have a vision in my head, I want James to execute it for me.
And although I must prefer the former let-me-have-at-it approach, because they’ll generally get better results with it, I don’t mind executing the former, this Author’s Vision.
But …
And here’s comes the ‘but’, we’re not going to get exactly the image they have in their head. And this blog might help them understand why not. And how we need to approach their book cover, their vision.
So this blog post is for them! But even if that’s not you — you might even be somewhat in between both of these sorts of people — this blog should help you understand AI image generation a bit better.
If you don’t want to read this whole blog, and it’s bit of a long one, and just want a TL;DR:

But if you want to know the reasons behind it all, and understand AI, stick with this blog and I’ll show you the man-behind-the-curtain, i.e. my life, trying to make your great book cover.
This blog post should dispel a lot of the myths I think authors have built up in their head about how easy and low-effort AI is. And in dispelling these myths, and actually understanding how I do what I do, it should make my life easier.
Because I think there is a lot of confusion at the moment.

So let’s start off with a topic which most authors probably think they have a good grasp of ‘Description in Fiction’. But before we do that, there’s quite a bit to cover, so grab yourself a lovely Earl Grey tea and a croissant, get comfy, and let’s have a look at it all.

Visual Imagination Greatest Joke
Before we talk about the problem that AI runs into, let’s have a little chat about how description in fiction actually works. Because I think this explains one really big problem with AI in a very perfectly succinct way.
All authors have an implicit feeling with how visual imagination works. When they’re writing something they’ll have a vision in their head of the scene, what the characters look like, maybe what’s happening in the background. Authors will see it in their mind’s eye and then their job is to effectively write that description down in words, so that readers will see exactly the same thing in their heads. Right?
Wrong.
Here’s the catch: readers won’t see exactly the same thing! Ever! They build their own picture in their own mind’s eye from the author’s words.

It’s literally how fiction functions. Good fiction gives you enough description and story to build the picture, whilst making sure the narrative moves forward.
So how could you get a reader to see what you see, as the author?
One solution would be to rely on that old adage: a picture tells a thousand words, right?
So what will you do as the author? Are you going to write a thousand words for each scene? For each character? So the reader sees exactly the same thing as you.
No, that would just mean the prose would become clunky and full of description and the story would move along at a glacial speed.
So what authors actually do is economise on description and give in to the fact that what they see in their own mind’s and the reader’s mind’s eye are never going to be the same thing, but close enough so we can carry the story forward at a nice pace.
In short, as authors we give ‘enough’ detail, not ‘excruciating’ detail.
This is important to remember when it comes to AI, because what MidJourney likes is that ‘enough’ detail, and doesn’t play well with ‘excruciating’ detail. Just like our readers.
What authors need to remember is this what’s happens:

And this is perfectly fine. In fact it has to be this way.
So why explain this?
When an author comes to be with their Author Vision for a book cover, what they’re doing is holding onto that first image. And I get caught in a hellscape of trying to match it. Our image on the left.
But if you’re following me so far, I’m sure you can see the glaring obvious problem here.
Just like a reader, with their own visual imagination, of the words that have been offered by the author to explain something visually, I’m in the same boat as a designer.
And here’s where it gets even more farcical.
There’s a third person in this process. And that’s MidJourney. So you have three different people being told words, and making pictures in their head from those words.
So authors tell me words to tell MidJorney, to make those images, like it is some sort of game of telephone. It’s a bit frustrating to say the least.
But I can see the cogs in your mind turn, as an author.
Wouldn’t it be much easier if we cut out James. Let me talk directly to MidJourney. Oh, and I know I’ll just give it loads of description! All that excruciating detail. That’d work. Right?
Nope.
Firstly, you might have heard of something called ‘prompt craft’ when it comes to generating images. It’s basically the way you talk to the AI so you can get the right thing out of the system in the way you want. And to put it into context, I’ve committed an hour every morning before I start work proper, every single day, over the last couple of years, to actually learning and understanding prompt craft. So good luck with that.
There’s two sorts of people in this world. Those that have played with AI image generation and seen how unruly it is, and how difficult it is to get it to behave, to get what you want.
And those yet to try AI image generation.
So that’s problem number one. It’s going to be a frustrating experience for you.
In fact, those two images of the ‘cat lazing under the tree’ were actually me asking MidJourney to literally draw a picture of a ‘cat lazing under a tree’. It interpreted my words in two different ways because I didn’t specify more than that.
And your second thought about it might be: I know what I’ll do I’ll just give it lots and lots of description then! Job done!
Something like:

Okay, let’s try that exact description with MidJourney and see what happens to try and get closer to the author’s mind’s eye image.
Here are the first four outputs from the description.

Welcome to my world! And the world of AI image generation.
If you want a feeling for the frustration you’re going to get being me then go have a play with one of the free image generation tools: ChatGPT, Co-pilot or Gemini. And you’ll soon understand.
So let’s have a chat about why this is happening and how we can fix it.
Chucking Water
Even if an author gives me loads of excruciating detail, like in that cat example, why isn’t MidJourney giving us images that are 100% perfect and match what we’ve asked for?
The simple answer is: technically, I have no idea!
All I’ve got is a feeling. A feeling I can best describe in terms of an analogy, one I like to call ‘The Random Chucking of the Water’.
The best way to visualise it for me — and explain it to you — is to think of it like each individual element we ask it for in that long description as a cup we want the water to fall in, everytime we re-roll a prompt to generate an image. And we’re chucking a big bucket of water at those containers. To see what sticks.
So our prompt my look something like this:

And then when we run the prompt, chuck the water, and hope it lands in the right descriptive places.
Let’s place some bets on whether that will work or not.
Yeah, generally this is what happens:


What we’re ideally looking for is this!

And that’s why the chucking water analogy works so well. Because you could try a million times and it’s not going to land in all the glasses equally as you want. It just won’t happen. Re-rolling prompts is more like some daft messy task on Taskmaster, where the studio audience is laughing at you. Rather than a precise art. By the way, all the Taskmaster Episodes are online here, and they’re very funny.
So it’s never going to produce a perfect image, hitting all of your descriptive elements and getting them all right.
But another reason why I really like the glass and bucket metaphor is because imagine we actually cut down the amount of descriptive elements, what would that look like?
I’ll take some bets again on how you think that is going to turn out.
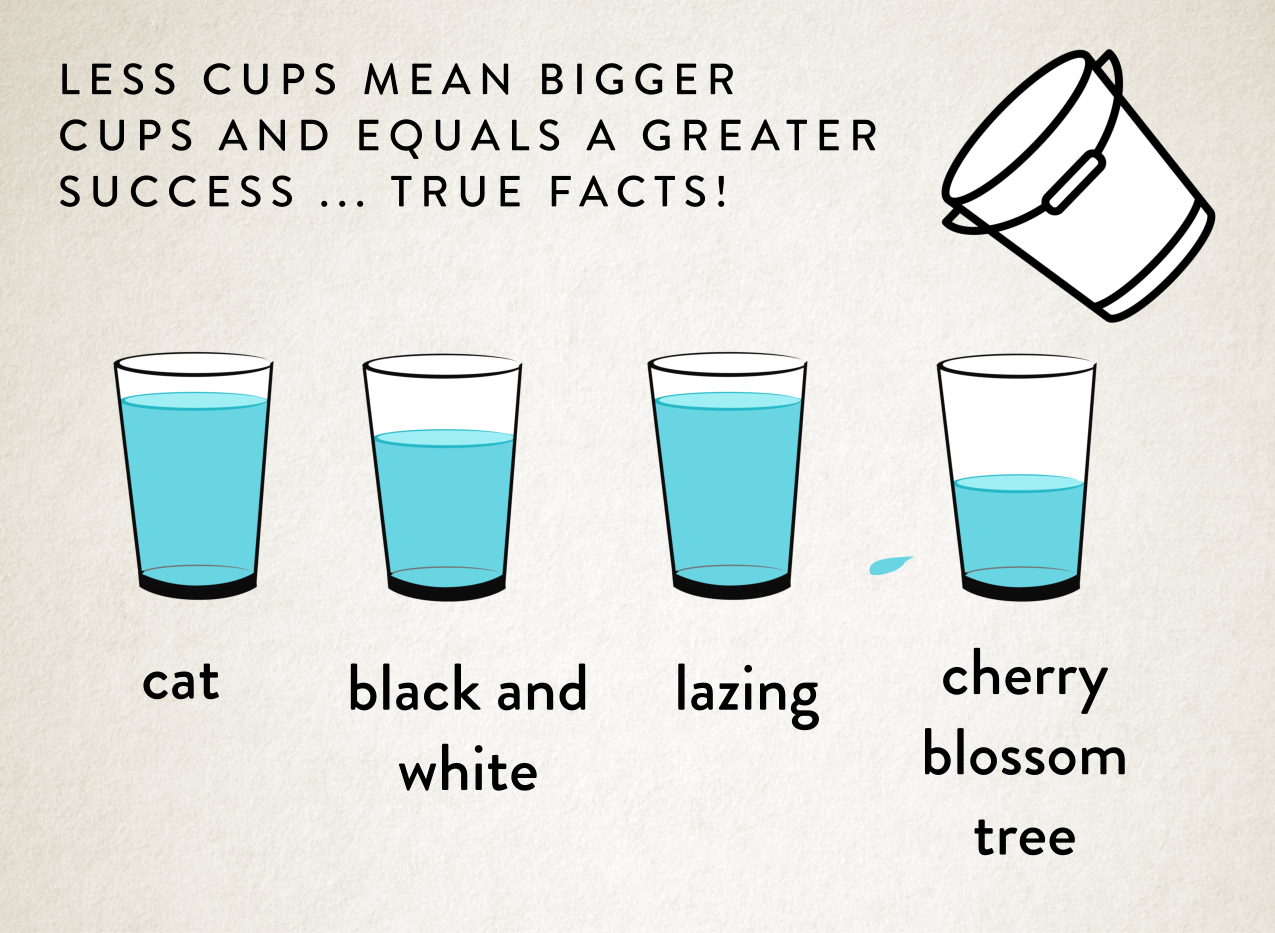
Of course. It definitely works a lot better! The water hits the right glass a lot more of the time!
But what this means is that authors who want an image to be more correct, need to let go of their Author’s Vision, because sorry, it just isn’t going to happen. There are limitations to what AI can and can’t do. The number of descriptors it’s going to hit correctly.
There simply needs to be compromises and authors need to trust me that I have their best interests at heart and I’m trying my hardest to get things right for them. Making the best images to make book covers from.
There needs to be a meeting in the middle.
But how do we achieve that?
Prioritise! Prioritise! Prioritise!
Firstly, we’ve learnt from our ‘Chucking Water’ analogy MidJourney is better when it has less cups to aim at. So much better. So firstly, we need to prioritise.
We need to trim the fat from the vision you have in your head. Make your idea a bit more amorphous to actually hit our really important points.
Ironically, this is what makes a better book cover anyway, hitting the three or four really important tonal, premise or plot points. Rather than an overly complex, detailed visual mess. Think more iconic album cover, rather than a movie still.
And is it really that important that the cat is black and white? That the tree is a cherry tree? Will it make any difference to a potential reader’s experience stumbling on your book cover if these things aren’t 100% accurate?
I would say ‘no’. If you asked me I’d take eye-catching over correct detail every time.
And maybe I’ve already taken up two of the descriptive elements I’m using in my prompt to make sure your cover is tonally correct and eye-catching. So that’s two less you’ve got to play with!
As we’ve learnt, if we try to give MidJourney our 300 word detailed description to explain your perfect image we’re definitely going to get the water splashing everywhere. So I would say the limit for any image is probably five or six descriptive elements. In order! And as I said, I probably want to take two of those, as the designer, to get tone and the medium right.
So that’s four things you can probably tell about your image.
Simply let go of the details in your head. It’s easy. What are your top five things? The age, the race, the hair colour, what they’re doing, what they’re wearing and … nope, that’s it. We’ve already gone over those four water containers to get consistent results.
Crazy, I know.
So you need to think of your most important story specific elements that you want on the book cover, and when I generate images just pick the coolest, eye-catching image. Because you’re not going to get everything you want. It’s the nature of the beast.
There’s actually a really good blog post, I wrote, about how to extract your most important details from a book for great cover here.
I’ll repeat it again: Forget about details. We’re after great emotive, eye-catching images that tell a story. Not the details. We can’t do detail.
Unfortunately, MidJourney isn’t very good at being detail-oriented.
So for me as a book cover designer, if we’re going down an AI route with a commission I like to know what’s important to you, in order! It’s helpful.
Details might be important to you, but they’re just not that important to MidJourney. It might improve with version seven or eight, but I wouldn’t hold my breath because from version five to six it was meant to improve and it didn’t.
Save your details for the inside of a book. You know, your writing.
And I know I’m banging one about ‘details’ here and you’re going to say to me: but everything is important! All my details. The vision in my head.
And I’m going to say: but that’s not the way it works, Veruca Salt. You can’t have an Oompa Loompa.

And cutting down your priorities gives better results, it’s the only way we can cut down all the randomness MidJourney generates. And give us strong usable images.
And you could say to me: but keep generating until all the water lands in my seventeen different glasses, it should eventually! Keep doing it! Keep doing it, NOW!
Sorry, not going to happen because time is very much limited, and I’m not just just talking about my precious designing time, we need to talk about …
Working on GPU Time
There’s a fantastic joke by Simon Munnery:
“They did give infinite typewriters to infinite monkeys. It’s called the internet.”

Okay, the original saying is something like: infinite typewriters plus infinite monkeys would equal the complete works of Shakespare.
My point being, given an infinite number of generations on MidJourney we could come up with the image that is in an author’s mind’s eye. Simple.
Well, apart from the fact that I don’t have an infinite amount of time to work on infinite images. I have a dinner date at 8pm today for starters.
And then comes the heavier catch.
I don’t have infinite GPU time.
With MidJourney I get 30 GPU hours a month to play with, basically the service generating the images is some cloud computing set-up, doing all the fancy stuff behind the scenes, and then giving me what it’s generated.
Basically around 150-200 images equals about 1 hour of GPU time.
Which sounds like a lot of images to pick from but there is a vast amount of redundancy!
Generally over the last couple of years what I’ve found is that if I have a project where an author has commissioned me, say for a single cover, I will generate about 300 images and about 25-30 images will be good enough to show the author to choose from.
There is a whopping 90-95% which is simply just trash. Unpresentable.

Images where the water has gone everywhere, and I know it’s not what an author has asked for. Or doesn’t look right in terms of tone. Or bad composition. Or has funny limbs. Or the colours are yucky. Or MidJourney interpreted my words in a rather amusing way. On and on.
So for each set of images I need to produce for a cover, I’m usually using up 1-2 hours of my GPU time. As well as the time of perfecting my prompt to get great images, with usually about 3-4 hours of human time too!
It would be great if I had infinite GPU time but that’s actually not possible. So unfortunately it can’t work any other way!
It would be utterly wonderful if an AI could read an author’s mind, do exactly what you tell it.

And I think sometimes authors think if they just give me more words and if I work hard enough it’ll happen.
It. Will. Not.
Plus I’m running out of GPU time — and patience.
So the watchword here I think is: compromise. Because as we learnt earlier communicating an Author’s Vision is ineffective with mere language.
There is a more powerful tool at an author’s disposal for getting great images with MidJourney, when I’m doing a commission for them, if they’re willing to open their mind.
But let’s start off with something simple before we get to them …
MidJourney Tools
Once we’ve decided on an image out of those 20-30 images I present to an author. Then we do have the possibility for MidJourney to edit that image within certain limitations.
The big one, for me, and it’s super practical, is probably panning. Without panning I wouldn’t have any space for your lovely title.
Here’s an example:

Also, and here’s another big one, is we can actually reroll parts of the image.
“Great, that means I can change a hairstyle to whatever I want, right? Change clothes. We’ll do all that later, then?”
Nope. Not so fast.
Because we can only replace rectangles of that image. So if that rectangle goes over something you do and don’t want to change, it will change both things. Also it’s not always perfect. We get messy results. Because we’re back to that 90% redundancy of duff rerolls.
Here’s an example of what I mean of your hair style idea.
[PIC]

Pretty bad right? How about if we just change some smaller elements. Let’s try a couple of experiments.


So there are some edits possible but only if an author can think in terms of squares and be prepared for me to turn around and say, “that didn’t even work.”
But my more powerful solution at our disposal, but less MidJourney related …
Give Thanks for the Happy Accident
I’m going to ask you, as an author, if we only have 4 or 5 descriptive elements to go on, which would you prefer to see: Ten images that are very similar which match your vision or ten images that are completely different in styles?
For me, I’m very much in the latter camp. Simple because choice is good. And it’s what MidJourney is really good at. Trying out lots of different crazy ideas.
Having a set vision in our head limits us to all the possibilities out there in the universe. And me, I’m a happy traveller with a vague destination in mind and try not to hamper myself with too many expectations.
In this way visual creation is very different to telling a story. With writing you’re always going somewhere, a story is linear, but with the visual arts you get to play and explore until you stumble on something truly fantastic.

It’s the only way happy accidents occur.
In fact, MidJourney works best when you push it to the edges. It even has its own parameter which I’m a master at, which is called ‘Chaos’. What a great name!
And given enough chaos and seemingly disparate concepts it comes up with all manner of fun things! And do you know what a good premise for a book is about, yep, you guessed it disparate concepts. It’s literally the best tool for making ace images for a book cover.
And the more you create an environment for me to play in, the more interesting images come out of the whole process. Allowing me to explore rather than sticking to a set vision. Like playing with Sref, which we talked about in my last post.
But the catch is, to go down that avenue you need to let go of the image you might have in your head and …
Be More Vibes-based Author and Less Details-oriented
I know this is hard for some authors that commissions me, but it’s a powerful way to get a powerful cover. And it’s how MidJourney actually works best. How I work best. Yep, my happy place.
But if we are trying to follow your vision, which I don’t mind doing either, you just need to remember you can half your cakes and eat it, but only half the cake!
So to Recap
When undertaking a commission with me where you have something very specific in mind, then you need to think what are your priorities for that image. Because MidJourney can’t do it all. If only. And hope that this post has helped explain why it can’t do it all. How it all actually works.
So I need something like:
- It need to be in a soft illustrated style like X cover
- She’s ditzy looking because it’s a plot point
- She’s walking in the Dartmoor National Forest
- She’s wearing bright yellow waterproofs
- She has a Jack Russel dog with her
After about point five, MidJourney is going to start to get very confused.

So you’ll need to forget about all those other facts you might want:
- She has a bob haircut with bangs …
- It’s mousey in colour …
- The dog has a spot over his left eye …
- She’s carrying a nobbled branch as a walking stick …
- It’s about 6pm in the evening …
- On the 19th of November …
- And there is a slight South-westerly breeze …
- and you can see a village in the background …
- On and on …
But if you promise to let go of detail, I’ll promise to create you the best image I possibly can, to design you a great book cover.
And with that I’m signing off writing this blog, and signing-on to getting on with some of these commissions I have stacked up already.
Until next time I will remain one educational …
James,
































